本篇文章是第一个lab的记录
完成了基础的实验室内容
挑战练习有时间会再看看
官网链接:Lab: Xv6 and Unix utilities
代码仓库:Github
启动xv6(难度:Easy)
之前已经搭建好环境并且下载好xv6了。
进入到对应的路径并且切换到util分支上:
$ cd xv6-labs-2020
$ git checkout util
Branch 'util' set up to track remote branch 'util' from 'origin'.
Switched to a new branch 'util'
xv6-labs-2020 存储库与本书的 xv6-riscv 略有不同;它主要添加一些文件。如果好奇,请查看 git 日志:
$git log
将使用Git版本控制系统分发此和后续实验室作业所需的文件。上面切换到了一个分支 ( git checkout util),其中包含为该实验室量身定制的 xv6 版本。要了解有关 Git 的更多信息,请查看 Git 用户手册,或者,您可能会发现这个 面向 CS 的 Git 概述很有用。Git 允许您跟踪您对代码所做的更改。例如,如果您完成了一项练习,并且想要检查您的进度,您可以通过运行以下命令来提交您的更改:
$ git commit -am 'my solution for util lab exercise 1'
Created commit 60d2135: my solution for util lab exercise 1
1 files changed, 1 insertions(+), 0 deletions(-)
git diff 您可以使用该命令 跟踪您的更改。运行git diff将显示自上次提交以来对您的代码git diff origin/util所做的更改,并将显示与初始 xv6-labs-2020 代码相关的更改。在这里,origin/xv6-labs-2020是 git 分支的名称,其中包含您为该类下载的初始代码。
构建并运行 xv6:
$ make qemu
riscv64-unknown-elf-gcc -c -o kernel/entry.o kernel/entry.S
riscv64-unknown-elf-gcc -Wall -Werror -O -fno-omit-frame-pointer -ggdb -DSOL_UTIL -MD -mcmodel=medany -ffreestanding -fno-common -nostdlib -mno-relax -I. -fno-stack-protector -fno-pie -no-pie -c -o kernel/start.o kernel/start.c
...
riscv64-unknown-elf-ld -z max-page-size=4096 -N -e main -Ttext 0 -o user/_zombie user/zombie.o user/ulib.o user/usys.o user/printf.o user/umalloc.o
riscv64-unknown-elf-objdump -S user/_zombie > user/zombie.asm
riscv64-unknown-elf-objdump -t user/_zombie | sed '1,/SYMBOL TABLE/d; s/ .* / /; /^$/d' > user/zombie.sym
mkfs/mkfs fs.img README user/xargstest.sh user/_cat user/_echo user/_forktest user/_grep user/_init user/_kill user/_ln user/_ls user/_mkdir user/_rm user/_sh user/_stressfs user/_usertests user/_grind user/_wc user/_zombie
nmeta 46 (boot, super, log blocks 30 inode blocks 13, bitmap blocks 1) blocks 954 total 1000
balloc: first 591 blocks have been allocated
balloc: write bitmap block at sector 45
qemu-system-riscv64 -machine virt -bios none -kernel kernel/kernel -m 128M -smp 3 -nographic -drive file=fs.img,if=none,format=raw,id=x0 -device virtio-blk-device,drive=x0,bus=virtio-mmio-bus.0
xv6 kernel is booting
hart 2 starting
hart 1 starting
init: starting sh
$
如果您在提示符下键入ls,您应该会看到类似于以下内容的输出:
$ ls
. 1 1 1024
.. 1 1 1024
README 2 2 2059
xargstest.sh 2 3 93
cat 2 4 24256
echo 2 5 23080
forktest 2 6 13272
grep 2 7 27560
init 2 8 23816
kill 2 9 23024
ln 2 10 22880
ls 2 11 26448
mkdir 2 12 23176
rm 2 13 23160
sh 2 14 41976
stressfs 2 15 24016
usertests 2 16 148456
grind 2 17 38144
wc 2 18 25344
zombie 2 19 22408
console 3 20 0
这些是mkfs包含在初始文件系统中的文件;大多数是您可以运行的程序。您只运行了其中一个:ls。
xv6 没有ps命令,但是,如果您键入Ctrl-p,内核将打印有关每个进程的信息。如果您现在尝试,您将看到两行:一行用于init,另一行用于sh。
要退出 qemu,请输入:Ctrl-a x.
sleep(难度:Easy)
为 xv6实现 UNIX 程序sleep;您的sleep应该暂停用户指定的滴答数。单个滴答(tick)是 xv6 内核定义的时间概念,即来自计时器芯片的两次中断之间的时间。您的解决方案应该在文件 user/sleep.c中。
提示:
- 在开始编码之前,请阅读《book-riscv-rev1》的第 1 章。
- 查看 user/ 中的其他一些程序(例如
user/echo.c、user/grep.c和user/rm.c),了解如何获取传递给程序的命令行参数。 - 如果用户忘记传递参数,sleep 应该打印一条错误消息。
- 命令行参数作为字符串传递;您可以使用
atoi将其转换为整数(请参阅 user/ulib.c)。 - 使用系统调用
sleep。 - 请参阅kernel/sysproc.c以获取实现
sleep系统调用的xv6内核代码(查找sys_sleep),user/user.h提供了sleep的声明以便其他程序调用,用汇编程序编写的user/usys.S可以帮助sleep从用户区跳转到内核区。 - 确保
main调用exit()以退出程序。 - 将你的
sleep程序添加到Makefile中的UPROGS中;完成后,make qemu将编译您的程序,您将能够从 xv6 shell 运行它。 - 查看 Kernighan 和 Ritchie 的书 《The C programming language (second edition) (K&R)》 以了解 C。
从xv6 shell运行程序:
$ make qemu
...
init: starting sh
$ sleep 10
(nothing happens for a little while)
$
如果程序在如上所示运行时暂停,则解决方案是正确的。运行make grade看看你是否真的通过了睡眠测试。
请注意,make grade运行所有测试,包括下面作业的测试。如果要对一项作业运行成绩测试,请键入(不要启动XV6,在外部终端下使用):
$ ./grade-lab-util sleep
这将运行与sleep匹配的成绩测试。或者,您可以键入:
$ make GRADEFLAGS=sleep grade
效果是一样的。
实现:
首先观察user/echo.c、user/grep.c和user/rm.c得知命令行参数是这样获取:
int main(int argc, char *argv[]) {
- argc 是第一个参数,表示一共获取到多少个传参
- argv是第二个参数,char*型的argv[],为字符型数组,存放命令行参数
在./user/user.h中查看sleep函数的声明如下:
int sleep(int);
只支持一个int参数。
写出的sleep函数如下:
#include "kernel/types.h"
#include "user/user.h"
int main(int argc, char *argv[]) {
// no arguments or too many arguments
if (argc != 2) {
fprintf(2, "usage: grep sleep [duration]\n");
exit(1);
}
// use atoi convert string to int
sleep(atoi(argv[1]));
exit(0);
}
根据提示使用了atoi将字符串转换为整数
注意:需要引入kernel/types.h,不然会有 error: unknown type name 'uint'
在make qemu之前,要在Makefile文件中的UPROGS添加sleep,否则文件不会被编译
UPROGS=\
$U/_cat\
$U/_echo\
$U/_forktest\
$U/_grep\
$U/_init\
$U/_kill\
$U/_ln\
$U/_ls\
$U/_mkdir\
$U/_rm\
$U/_sh\
$U/_stressfs\
$U/_usertests\
$U/_grind\
$U/_wc\
$U/_zombie\
$U/_sleep\ # <- 加到这里了
然后运行xv6进行测试,因为sleep是通过tick进行计时的,所以sleep 10会很快结束
$ make qemu
...
init: starting sh
$ sleep 10
(nothing happens for a little while)
$ sleep 200
(nothing happens for a longer while)
$ sleep
usage: grep sleep [duration]
$ sleep 50 50
usage: grep sleep [duration]
运行python测试后得到报错:
$ ./grade-lab-util sleep
/usr/bin/env: ‘python\r’: No such file or directory
是编码问题,安装另外一个包解决:
sudo apt-get install dos2unix
dos2unix ./grade-lab-util
尝试运行,依然存在报错:
/usr/bin/env: ‘python’: No such file or directory
安装另外一个包进行修复:
sudo apt install python-is-python3
好耶!现在跑起来完全没有问题,测试也通过了
make: 'kernel/kernel' is up to date.
== Test sleep, no arguments == sleep, no arguments: OK (2.0s)
== Test sleep, returns == sleep, returns: OK (1.1s)
== Test sleep, makes syscall == sleep, makes syscall: OK (1.1s)
pingpong(难度:Easy)
编写一个使用UNIX系统调用的程序来在两个进程之间“ping-pong”一个字节,请使用两个管道,每个方向一个。父进程应该向子进程发送一个字节;子进程应该打印“<pid>: received ping”,其中<pid>是进程ID,并在管道中写入字节发送给父进程,然后退出;父级应该从读取从子进程而来的字节,打印“<pid>: received pong”,然后退出。您的解决方案应该在文件user/pingpong.c中。
提示:
使用
pipe来创造管道使用
fork创建子进程使用
read从管道中读取数据,并且使用write向管道中写入数据使用
getpid查找调用进程的进程 ID。将程序添加到Makefile 中的
UPROGS。xv6 上的用户程序有一组有限的库函数可供他们使用。您可以在
user/user.h中看到列表;源(系统调用除外)位于user/ulib.c、user/printf.c和user/umalloc.c中。
运行程序应得到下面的输出
$ make qemu
...
init: starting sh
$ pingpong
4: received ping
3: received pong
$
如果您的程序在两个进程之间交换一个字节并产生如上所示的输出,那么您的解决方案是正确的。
实现:
因为需要在两个进程之间交换一个字节,而一个pipe是单向的(只能从写端到读端),所以我们需要两个pipe,一个负责从父进程写入字节,然后被子进程读取。另外一个则相反。
父进程发送ping:
他首先需要关闭从自己到子进程管道的读端,然后开始写入字节,写入完成后关闭其写端
子进程接收ping:
他需要先关闭父线程到子线程的写端,然后读取字节,读取完成后关闭读端
子线程发送pong:
他首先需要关闭自己到父线程管道的读端,然后开始写入字节,写入完成后关闭其写端
父进程接受pong:
他需要先关闭子线程到父线程的写端,然后读取字节,读取完成后关闭读端
#include "kernel/types.h"
#include "user/user.h"
#define RD 0 // the read end of the pipe
#define WR 1 // the write end of the pipe
int main(int argc, char *argv[]) {
int ptc[2], ctp[2]; // 0 for read, 1 for write
// create pipe
pipe(ptc);
pipe(ctp);
char buf = 'P';
int pid = fork();
do {
if (pid > 0) {
// parent
close(ptc[RD]); // close read end of pipe
close(ctp[WR]); // close write end of pipe
// send the ping to the child
if (write(ptc[WR], &buf, sizeof(char)) != sizeof(char)) {
fprintf(2, "parent write error\n");
break;
}
// receive the pong from the child
if (read(ctp[RD], &buf, sizeof(char)) != sizeof(char)) {
fprintf(2, "parent read error\n");
break;
} else {
fprintf(1, "%d: received pong\n", getpid());
}
close(ctp[WR]); // close write end of pipe
close(ptc[RD]); // close read end of pipe
} else if (pid == 0) {
// child
close(ptc[WR]); // close write end of pipe
close(ctp[RD]); // close read end of pipe
// receive ping from the parent
if (read(ptc[RD], &buf, sizeof(char) != sizeof(char))) {
fprintf(2, "child read error\n");
break;
} else {
fprintf(1, "%d: received ping\n", getpid());
}
// send pong to the parent
if (write(ctp[WR], &buf, sizeof(char)) != sizeof(char)) {
fprintf(2, "child write error\n");
break;
}
close(ctp[RD]); // close read end of pipe
close(ptc[WR]); // close write end of pipe
} else {
break;
}
exit(0); // success exit
} while (0);
// error cases
fprintf(2, "error\n");
close(ptc[RD]);
close(ptc[WR]);
close(ctp[RD]);
close(ctp[WR]);
exit(1);
}
read(fd,buf,n)系统调用从文件描述符fd读取最多n字节,将它们复制到buf,返回读取的字节数。write(fd,buf,n)系统调用将buf中的n字节写入文件描述符fd,并返回写入的字节数。
注:用了do和while充当try和catch
Primes(素数,难度:Moderate/Hard)
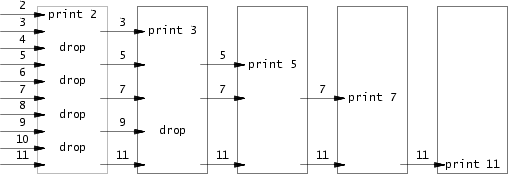
使用管道编写一个并发版本的初筛。这个想法归功于 Unix 管道的发明者 Doug McIlroy。本页中间的图片 和周围的文字说明了如何做到这一点。您的解决方案应该在文件user/primes.c中。
您的目标是使用pipe和fork来设置管道。第一个过程将数字 2 到 35 输入管道。对于每个素数,您将安排创建一个进程,该进程通过管道从其左邻居读取并通过另一管道向其右邻居写入。由于 xv6 的文件描述符和进程数量有限,第一个进程可以在 35 处停止。
提示:
小心关闭进程不需要的文件描述符,否则你的程序将在第一个进程达到 35 之前运行 xv6 资源不足。
一旦第一个进程达到35,它应该使用
wait等待整个管道终止,包括所有子孙进程等等。因此,主primes进程应该只在打印完所有输出之后,并且在所有其他primes进程退出之后退出。提示:当管道的
write端关闭时,read返回零将 32 位(4 字节)的
int直接写入管道是最简单的,而不是使用格式化的 ASCII I/O。您应该仅在需要时在管道中创建流程。
将程序添加到Makefile 中的
UPROGS。
如果您的解决方案实现了基于管道的筛选并产生以下输出,则是正确的:
$ make qemu
...
init: starting sh
$ primes
prime 2
prime 3
prime 5
prime 7
prime 11
prime 13
prime 17
prime 19
prime 23
prime 29
prime 31
$
原始网页的翻译:
考虑生成小于一千的所有素数。Eratosthenes 的筛子可以通过执行以下伪代码的流程管道来模拟::
p = 从左邻居获取一个数
print p
循环:
n =
如果(p 不除 n)
将 n 发送到右邻居,则从左邻居获取一个数
生成进程可以将数字 2, 3, 4, …, 1000 输入管道的左端:行中的第一个进程消除 2 的倍数,第二个消除 3 的倍数,第三个消除5的倍数,以此类推:
实现:
#include "kernel/types.h"
#include "user/user.h"
#define RD 0
#define WR 1
// the child receives the primes from the parent
void primes(int *p);
// print the first prime and return it
int get_first_prime(int *p);
// transmit the data to the next child
void transmit_data(int *p, int *p_next, int val);
int main(int argc, char *argv[]) {
int p[2]; // 0 for read and 1 for write
pipe(p);
for (int i = 2; i <= 35; i++) {
write(p[WR], &i, sizeof(int));
}
int pid = fork();
if (pid < 0) {
printf("fork failed\n");
close(p[RD]);
close(p[WR]);
exit(1);
} else if (pid == 0) {
// child process
close(p[WR]);
primes(p);
close(p[RD]);
exit(0);
} else {
// parent process
close(p[RD]);
close(p[WR]);
wait(0);
exit(0);
}
}
void primes(int *p) {
int prime_num = get_first_prime(p);
int p_next[2]; // 0 for read and WR for write
pipe(p_next);
int pid = fork();
if (pid < 0) {
printf("fork failed\n");
// close the parent pipe
close(p[RD]);
close(p_next[RD]);
close(p_next[WR]);
exit(WR);
} else if (pid == 0) {
// child process
close(p[RD]);
close(p_next[WR]);
primes(p_next);
close(p_next[RD]);
exit(0);
} else {
// parent process
close(p_next[RD]);
transmit_data(p, p_next, prime_num);
close(p[RD]);
close(p_next[WR]);
wait(0);
exit(0);
}
}
int get_first_prime(int *p) {
int num;
int len = read(p[RD], &num, sizeof(int));
if (len == 0) {
// no data to read
close(p[RD]);
exit(0);
} else {
printf("prime %d\n", num); // print the first prime number
return num; // actually, the first received number must be the prime number
}
}
void transmit_data(int *p, int *p_next, int val) {
int num;
// continue to read the next number
while (read(p[RD], &num, sizeof(int))) {
if (num % val) {
write(p_next[WR], &num, sizeof(int)); // only write the prime number
}
}
}
注:其实就是使用递归新建管道,然后筛出符合条件的数,再传到子进程里
更新:
之前的实现写的有点长了,更新一个短一点的mini版
#include "kernel/types.h"
#include "user/user.h"
// 0 for read and 1 for write
#define RD 0
#define WR 1
void primes(int *p);
int main() {
int p[2];
pipe(p);
if (fork() == 0) { // child process
primes(p);
} else { // parent process
close(p[RD]);
for (int i = 2; i <= 35; i++) {
write(p[WR], &i, sizeof(int));
}
close(p[WR]);
wait(0);
}
exit(0);
}
void primes(int *p) {
int prime, num, p_next[2];
close(p[WR]);
if (read(p[RD], &prime, sizeof(int)) == 0) {
close(p[RD]);
exit(0);
}
printf("prime %d\n", prime);
pipe(p_next);
if (fork() > 0) { // parent process
close(p_next[RD]);
while (read(p[RD], &num, sizeof(int))) {
if (num % prime) {
write(p_next[WR], &num, sizeof(int));
}
}
close(p[RD]);
close(p_next[WR]);
wait(0);
} else { // child process
primes(p_next);
}
close(p[RD]);
}
find(难度:Moderate)
写一个简化版本的UNIX的find程序:查找目录树中具有特定名称的所有文件,你的解决方案应该放在user/find.c
提示:
- 查看user/ls.c文件学习如何读取目录
- 使用递归允许
find下降到子目录中 - 不要在
.和..目录中递归 - 对文件系统的更改会在qemu的运行过程中一直保持;要获得一个干净的文件系统,请运行
make clean,然后make qemu - 你将会使用到C语言的字符串,要学习它请看《C程序设计语言》(K&R),例如第5.5节
- 注意在C语言中不能像python一样使用“
==”对字符串进行比较,而应当使用strcmp() - 将程序加入到Makefile的
UPROGS
如果你的程序输出下面的内容,那么它是正确的(当文件系统中包含文件b和a/b的时候)
$ make qemu
...
init: starting sh
$ echo > b
$ mkdir a
$ echo > a/b
$ find . b
./b
./a/b
$
实现:
首先在主程序里面判断一下参数数量,然后find函数里面先检查一下存不存在,能不能获取stat,是不是dir,以及路径是否过长。通过测试之后,我们就能用while loop不断读取。如果当前目录是空的就直接返回,不然先把名字加到buf里面,然后读取stat。如果不能读取就下一个文件,当找到符合文件名字的时候直接打印。(因为刚刚已经把名字更新到buf内了)如果遇到文件夹就递归查询,同时注意不要在.和..目录中递归
#include "kernel/types.h"
#include "kernel/stat.h"
#include "user/user.h"
#include "kernel/fs.h"
void find(char *path, char *fileName) {
char buf[512], *p;
int fd;
struct dirent de;
struct stat st;
if ((fd = open(path, 0)) < 0) {
fprintf(2, "ls: cannot open %s\n", path);
return;
}
if (fstat(fd, &st) < 0) {
fprintf(2, "ls: cannot stat %s\n", path);
close(fd);
return;
}
if (st.type != T_DIR) {
fprintf(2, "find: %s is not a directory !\n", path);
close(fd);
return;
}
if (strlen(path) + 1 + DIRSIZ + 1 > sizeof buf) {
printf("find: path too long\n");
return;
}
// add the '/' to the path end
strcpy(buf, path);
p = buf + strlen(buf);
*p++ = '/';
while (read(fd, &de, sizeof(de)) == sizeof(de)) {
if (de.inum == 0)
continue;
memmove(p, de.name, DIRSIZ); // copy the name to the buffer
p[DIRSIZ] = 0; // add the null terminator
if (stat(buf, &st) < 0) {
printf("find: cannot stat %s\n", buf);
continue;
}
if (strcmp(de.name, fileName) == 0) {
printf("%s\n", buf);
} else if (st.type == T_DIR && strcmp(p, ".") != 0 &&
strcmp(p, "..") != 0) {
// do not recurse into the current directory or the parent directory
find(buf, fileName);
}
}
close(fd);
}
int main(int argc, char *argv[]) {
if (argc == 3) {
find(argv[1], argv[2]);
} else {
printf("usage: fing <PATH> <FILENAME>\n");
}
exit(0);
}
注:这部分有点不太理解,几个方法和结构体不是很熟悉,学习完文件系统再回头看这部分
xargs(难度:Moderate)
编写一个简化版UNIX的xargs程序:它从标准输入中按行读取,并且为每一行执行一个命令,将行作为参数提供给命令。你的解决方案应该在user/xargs.c
下面的例子解释了xargs的行为
$ echo hello too | xargs echo bye
bye hello too
$
注意,这里的命令是echo bye,额外的参数是hello too,这样就组成了命令echo bye hello too,此命令输出bye hello too
请注意,UNIX上的xargs进行了优化,一次可以向该命令提供更多的参数。 我们不需要您进行此优化。 要使UNIX上的xargs表现出本实验所实现的方式,请将-n选项设置为1。例如
$ echo "1\n2" | xargs -n 1 echo line
line 1
line 2
$
提示:
- 使用
fork和exec对每行输入调用命令,在父进程中使用wait等待子进程完成命令。 - 要读取单个输入行,请一次读取一个字符,直到出现换行符(’\n’)。
- kernel/param.h声明
MAXARG,如果需要声明argv数组,这可能很有用。 - 将程序添加到Makefile中的
UPROGS。 - 对文件系统的更改会在qemu的运行过程中保持不变;要获得一个干净的文件系统,请运行
make clean,然后make qemu
xargs、find和grep结合得很好
$ find . b | xargs grep hello
将对“.”下面的目录中名为b的每个文件运行grep hello。
要测试您的xargs方案是否正确,请运行shell脚本xargstest.sh。如果您的解决方案产生以下输出,则是正确的:
$ make qemu
...
init: starting sh
$ sh < xargstest.sh
$ $ $ $ $ $ hello
hello
hello
$ $
你可能不得不回去修复你的find程序中的bug。输出有许多$,因为xv6 shell没有意识到它正在处理来自文件而不是控制台的命令,并为文件中的每个命令打印$。
实现:
#include "kernel/types.h"
#include "kernel/param.h"
#include "user/user.h"
#define MAXSZ 512
enum state {
S_WAIT, // the initial state, or the current is a space
S_ARG, // the current char is a arg
S_ARG_END, // the end of the arg
S_ARG_LINE_END, // new line next to the arg, "abc\n"
S_LINE_END, // the new line next to the space, "abc \n"
S_END, // end, EOF
};
enum char_type { C_SPACE, C_CHAR, C_LINE_END };
enum char_type get_char_type(char c) {
switch (c) {
case ' ':
return C_SPACE;
case '\n':
return C_LINE_END;
default:
return C_CHAR;
}
}
enum state transform_state(enum state cur, enum char_type ct) {
switch (cur) {
case S_WAIT:
if (ct == C_SPACE)
return S_WAIT;
if (ct == C_LINE_END)
return S_LINE_END;
if (ct == C_CHAR)
return S_ARG;
break;
case S_ARG:
if (ct == C_SPACE)
return S_ARG_END;
if (ct == C_LINE_END)
return S_ARG_LINE_END;
if (ct == C_CHAR)
return S_ARG;
break;
case S_ARG_END:
case S_ARG_LINE_END:
case S_LINE_END:
if (ct == C_SPACE)
return S_WAIT;
if (ct == C_LINE_END)
return S_LINE_END;
if (ct == C_CHAR)
return S_ARG;
break;
default:
break;
}
return S_END;
}
void clearArgv(char *x_argv[MAXARG], int beg) {
for (int i = beg; i < MAXARG; ++i)
x_argv[i] = 0;
}
int main(int argc, char *argv[]) {
if (argc < 2) {
printf("xargs: minium amount of args is 2 !\n");
exit(1);
} else if (argc - 1 >= MAXARG) {
printf("xargs: maxium amount of args is %d !\n", MAXARG);
exit(1);
}
char lines[MAXSZ];
char *p = lines;
char *x_argv[MAXARG] = {0}; // used to store the args
// record all the args
// start 1 for skip the first space
for (int i = 1; i < argc; i++) {
x_argv[i - 1] = argv[i];
}
int start = 0;
int end = 0;
int current = argc - 1;
enum state st = S_WAIT; // the initial state
while (st != S_END) {
if (read(0, p, sizeof(char)) != sizeof(char)) {
st = S_END;
} else {
st = transform_state(st, get_char_type(*p));
}
if (++end >= MAXSZ) {
printf("xargs: arguments too long.\n");
exit(1);
}
switch (st) {
case S_WAIT:
++start;
break;
case S_ARG_END:
x_argv[current++] = &lines[start];
start = end;
*p = '\0';
break;
case S_ARG_LINE_END:
x_argv[current++] = &lines[start];
case S_LINE_END:
start = end;
*p = '\0';
if (fork() == 0) {
exec(argv[1], x_argv);
}
current = argc - 1;
clearArgv(x_argv, current);
wait(0);
break;
default:
break;
}
++p;
}
exit(0);
}
注:这部分是用了状态机,感觉跟之前写编译器的时候很像,有种莫名既视感。这部分也需要回头看一下